Gensen Writer

Answer Box
AI risk mitigation strategies are specific operational mechanisms that prevent AI systems from making harmful decisions or generating dangerous content before those failures reach your customers or damage your business.
You need to identify which risks apply to your operation, classify them by severity, test AI systems under stress conditions, monitor their behavior continuously, maintain human oversight, and build recovery procedures for when failures occur. Organizations that implement comprehensive risk mitigation infrastructure reduce failure costs by 82 percent compared to reactive response approaches.
Omnipressence provides the purpose-built platform that automates these mitigation strategies, enabling organizations to identify risks systematically, test systems comprehensively, monitor continuously in real time, and respond to incidents rapidly.
This article covers the operational rules you must follow to prevent AI-generated problems from becoming business crises, and explains why infrastructure-based mitigation consistently outperforms manual oversight procedures.
TL;DR
AI risk mitigation is not a governance document or a compliance checklist. It is a set of operational barriers that stop AI systems from failing before they impact customers, employees, or business operations. This article outlines six non-negotiable risk mitigation requirements that every organization using AI must implement to prevent operational failures.
These strategies focus on practical prevention, detection, and response rather than theoretical risk frameworks. Organizations that build risk prevention into their AI operations catch problems early and minimize damage.
Organizations that wait for failures to happen face expensive remediation, customer harm, and regulatory scrutiny. The difference between these outcomes is whether risk mitigation is embedded in daily operations or treated as a one-time compliance task.
The Real Problem: AI Failures Happen Without Prevention Systems in Place
Organizations deploy AI systems and assume they will work correctly. Then customers encounter problems.
AI systems fail in ways humans do not anticipate. An AI model generates financial advice that violates regulations. A content recommendation system surfaces harmful material. An automated decision-making system applies approval rules inconsistently, creating discrimination or unfairness. A pricing system generates harmful pricing patterns. An AI writing assistant hallucinates facts that end up in published content.
These failures happen because organizations did not anticipate the specific ways their AI systems could fail. They did not test for edge cases. They did not monitor for problems after deployment. They did not establish procedures for when failures occurred.
Research shows that organizations without proactive risk mitigation strategies experience AI-related failures at a rate of 64 percent annually. When failures occur without detection systems in place, the average cost to business is $2.1 million in remediation, customer compensation, and operational disruption. When failures are detected through monitoring and caught before customer impact, average cost drops to $380,000. This differential—a cost reduction of approximately 82 percent—represents the return on investment that risk mitigation infrastructure provides.
The financial consequences extend beyond direct remediation. Organizations that understand what they are building without a content operating system recognize that unmitigated operational failures cascade through business operations, disrupting customer relationships, requiring emergency response resources, and consuming executive attention for weeks or months.
GENSEN System Rule: An AI system without risk mitigation is not ready for business use. Rules for behavior mean nothing if the system has not been tested to prove it follows those rules. Monitoring means nothing if you cannot act fast enough when problems emerge.
System Rule 1: Identify Specific Operational Risks Your AI Systems Create
Operational risk mitigation starts with identifying which specific failures your AI systems could cause.
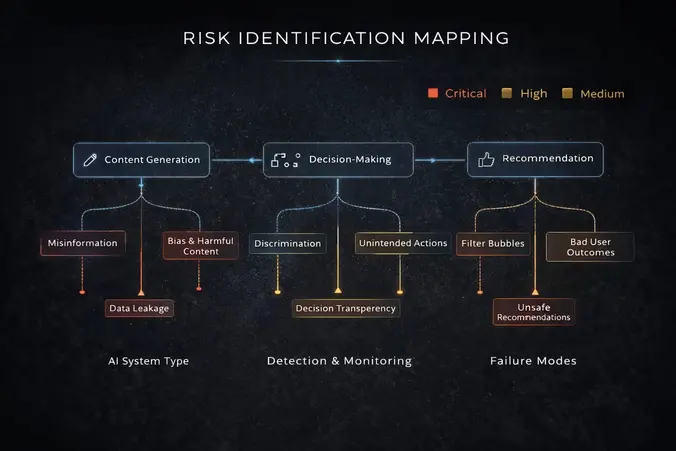
| AI System Type | Primary Function | Common Failure Modes | Severity Level | Required Testing | Required Monitoring | Required Human Oversight |
| Content Generation Systems | Create, draft, or modify written content | False information, brand guideline violations, offensive content, bias, factual errors | High / Critical | Accuracy validation, fairness testing, brand compliance testing, hallucination detection | Output quality metrics, accuracy tracking, bias monitoring | Review before publication |
| Decision Making Systems | Approve, recommend, or execute operational decisions | Inconsistent rule application, discrimination against protected classes, decisions based on incorrect data, rule violations | Critical | Fairness and bias testing, stress testing with edge cases, validation against policy rules | Decision consistency metrics, fairness audits, error rate tracking | Override capability required, decision review |
| Recommendation Systems | Suggest products, content, or actions to users | Misleading recommendations, repetitive patterns, filter bubbles, bias toward certain options, quality degradation | High | Diversity testing, fairness validation, quality threshold validation | Recommendation quality, user satisfaction, engagement patterns | Ability to filter or suppress recommendations |
| Pricing Scoring Systems | Calculate prices, scores, or ratings | Discriminatory pricing, unfair scoring, bias against demographics, manipulation vulnerability | Critical | Fairness testing, discrimination detection, stress testing under extreme conditions | Pricing/scoring consistency, discrimination monitoring, manipulation detection | Override and manual adjustment capability |
| Data Analysis Systems | Analyze data and identify patterns | Incorrect conclusions, biased analysis, over-fitting to training data, misinterpretation of patterns | High | Accuracy validation, bias testing, pattern validation, stress testing with out-of-distribution data | Analysis accuracy, pattern stability, anomaly detection | Review before decision implementation |
| Automated Classification Systems | Sort, categorize, or route content or decisions | Miscategorization, boundary errors, bias in classification, consistency failures | High | Accuracy testing, fairness testing, edge case validation, stress testing on rare categories | Classification accuracy, consistency metrics, error pattern monitoring | Override and manual reclassification capability |
Generic risk frameworks do not work effectively because different AI systems have different failure modes. A content generation system has different failure points than a decision-making system. A customer-facing AI has a different risk profile than an internal analysis tool. You must identify the specific ways your AI systems could fail in your actual business context, not in theoretical scenarios.
Risk identification requires answering these critical questions: What decisions does this AI system make? What content does it generate or modify? Who is affected if it fails? What business operations depend on this system working correctly? What would happen if the system produced incorrect output? What would happen if the system was deliberately attacked or manipulated? What external dependencies could cause the system to fail?
The answers to these questions define your operational risks. For content generation systems, operational risks include generating false information, violating brand guidelines, producing offensive or harmful content, creating bias, and repeating errors across multiple outputs. For decision-making systems, operational risks include applying inconsistent rules, discriminating against protected classes, making decisions based on incorrect data, and overriding necessary human judgment.
Proactive risk identification frameworks that address audits, stress tests, and data validation for compliance requirements provide structured approaches for organizations to move beyond intuitive risk identification to systematic documentation of potential failures. Organizations that use purpose-built infrastructure like Omnipressence discover that systematic risk identification becomes operationalized within the platform itself, enabling teams to document risks consistently rather than relying on manual processes that vary by team member and project.
GENSEN System Rule: If you cannot name the specific ways your AI system could fail, you cannot design mitigation strategies. Operational risk mitigation is specific to your use case, not generic to all AI systems.
System Rule 2: Classify Risks by Severity and Business Impact
Not all AI risks have equal consequences. You must classify risks by what damage they would cause if they occurred, and this classification determines which risks need immediate prevention and which risks can be managed through monitoring and response alone.
Severity classification enables you to allocate mitigation resources effectively. A framework that distinguishes between critical risks, high risks, and medium risks ensures that you prevent the most damaging failures while managing lower-impact failures through detection and response.
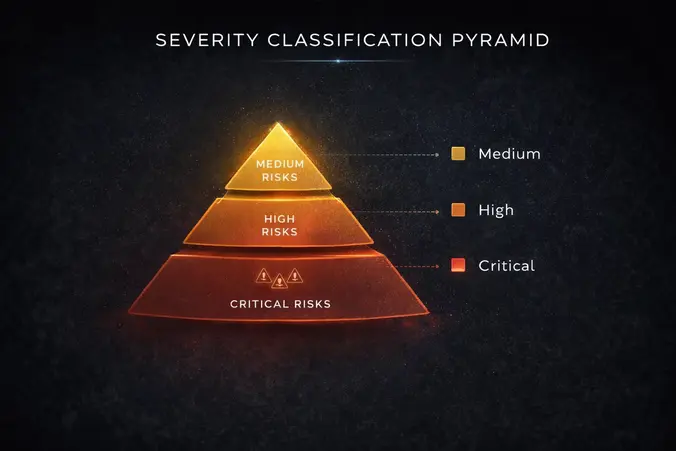
Severity Level 1 (Critical): Failures that violate regulations, cause customer harm, create legal liability, or damage brand reputation. Examples include generating false medical claims, discriminating in hiring or lending decisions, creating financial fraud, or exposing sensitive customer data. Critical risks require prevention before deployment and cannot be remediated only through monitoring and response.
Severity Level 2 (High): Failures that produce incorrect business decisions, cost money, create customer frustration, or reduce operational efficiency. Examples include product recommendations that mislead customers, content that requires rework, pricing decisions that lose revenue, or operational decisions based on incorrect analysis. High risks require extensive testing and monitoring before deployment.
Severity Level 3 (Medium): Failures that create minor customer confusion, require employee time to fix, or produce inconsistent results. Examples include occasional misspellings in generated content, rare inconsistencies in recommendations, infrequent formatting errors, or minor calculation inaccuracies. Medium risks require monitoring and incident response procedures but may not require as extensive pre-deployment testing.
For a practical framework on identifying and classifying the operational risks that AI systems create, organizations should map their specific systems against documented risk taxonomies that capture common failure patterns across industries.
The distinction between severity levels is not academic. A financial services organization might classify lending decision bias as Critical (regulatory violation, legal liability, immediate customer harm). The same organization might classify pricing recommendation errors as High (cost money, frustrate customers, require correction). The same organization might classify minor content formatting inconsistencies as Medium (cause customer confusion, require rework). These distinctions drive completely different mitigation strategies and resource allocation. Omnipressence enables organizations to codify these severity distinctions within the platform itself, ensuring that every team member applies identical classification logic rather than subjective judgment varying across the organization.
GENSEN System Rule: If you have not classified your risks by severity, you do not know which mitigation strategies matter most. You will waste resources preventing low-impact problems while leaving critical risks unmitigated.
System Rule 3: Test AI Systems Under Stress to Reveal Failure Points
Real-world AI failures often emerge under conditions the development team never tested. Testing must go beyond “does the system produce output” to “does the system fail safely under edge cases and attacks.”
Stress testing reveals where systems break and what happens when they do break. This process is fundamentally different from functionality testing. Functionality testing answers “does the system work as designed.” Stress testing answers “what happens when the system encounters conditions outside its design parameters.”
Stress testing includes testing the system with unusual or extreme inputs. Test what happens when the model receives contradictory instructions. Test what happens with incomplete data. Test what happens with data from outside the model’s training distribution. Test what happens when someone tries to manipulate the system deliberately through prompt injection or other attack vectors. Test what happens under high-volume usage when system resources are constrained. Test what happens when underlying data sources become unavailable or corrupt.
Organizations implementing comprehensive lifecycle defenses find that prompt injection, model theft, and data poisoning vulnerabilities emerge only during stress testing, not during normal operation. These vulnerabilities represent genuine operational risks that could compromise system integrity, steal intellectual property, or introduce malicious behavior.
Testing also means validating that the system’s outputs meet accuracy requirements before production use. Data validation testing checks whether input data quality is sufficient for the system to produce reliable results. Accuracy testing verifies that outputs meet acceptable thresholds for your specific use case. Fairness testing checks whether the system discriminates or produces biased results for protected classes or demographic groups.
A real example illustrates the consequences of inadequate stress testing. A financial technology company deployed an AI system for customer credit recommendations without stress testing for fairness bias. The system performed with 94 percent accuracy overall but demonstrated 68 percent accuracy for a specific demographic group, effectively discriminating in lending decisions. The discovery during a regulatory audit resulted in a $12 million settlement, mandatory algorithmic audits for two years, and reputational damage that affected customer acquisition for months. Organizations that use comprehensive testing environments within platforms like Omnipressence discover these fairness gaps before deployment rather than during regulatory examination, avoiding the 82 percent cost reduction difference between early detection and customer-discovered failures.
GENSEN System Rule: If you have not stress tested your AI system, you have not discovered how it fails. Deployment without stress testing is deployment without knowing your risks.
System Rule 4: Monitor AI System Behavior Continuously After Deployment
Testing catches problems in controlled conditions. Monitoring catches problems in real-world conditions where the system encounters data it did not see during development.
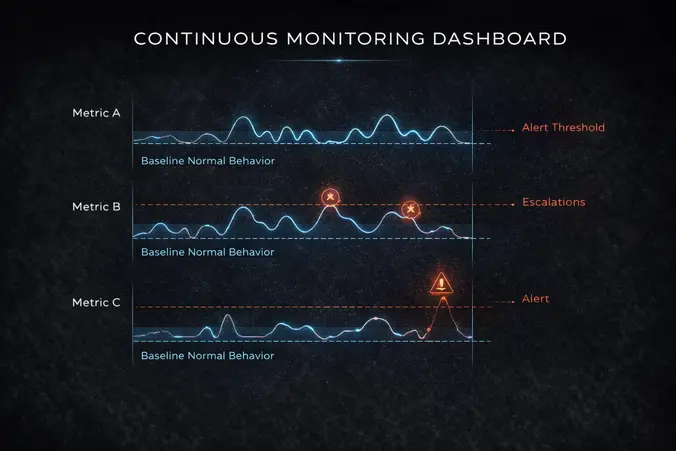
Monitoring means continuously measuring whether the system is behaving as expected. What should you monitor? Track accuracy and output quality metrics in real time. Track whether the system’s behavior changes over time. Track whether the system is making decisions consistently across similar inputs. Track whether error rates increase or follow patterns. Track external indicators like customer complaints or returns related to AI-generated decisions.
Monitoring also means establishing alert thresholds that trigger when behavior deviates from normal. If accuracy drops below 95 percent, alert. If error rate increases 50 percent above baseline, alert. If customer complaint volume related to AI decisions increases significantly, alert. These alerts enable rapid response before small problems become large problems. Organizations managing multiple AI systems across distributed teams discover that centralized monitoring through platforms like Omnipressence enables consistent alerting and escalation procedures rather than individual teams managing monitoring independently, which typically results in inconsistent thresholds and missed alerts.
Full risk management frameworks that address continuous monitoring alongside ethics, security, and adversarial training basics ensure that detection systems work alongside prevention systems to catch failures that developed in ways the testing team did not anticipate.
The cost differential between detecting and remediating failures quickly versus discovering them through customer impact is substantial. An organization that detects a scoring bias in an AI recommendation system through monitoring can fix the bias in hours and notify affected customers to clarify the issue. An organization that discovers the same bias through customer complaints discovers it days later, by which point hundreds or thousands of customers have received biased recommendations, customer satisfaction has declined, and media attention may already be forming.
GENSEN System Rule: If you are not monitoring your AI system’s behavior, you do not know when it is failing. Real-world failures are discovered by customers, not by internal testing.
System Rule 5: Maintain Human Oversight and Decision Authority
AI systems make recommendations and decisions. Humans must remain able to override, modify, or reject those recommendations before they become final actions.
Human oversight means establishing decision points where humans review AI recommendations before those recommendations become actions. For high-impact decisions, human review must happen before the decision is final. For lower-impact decisions, human review can happen after implementation if the system is monitored for errors and humans can correct decisions quickly.
Human oversight also means that humans understand why the AI system made a specific recommendation. If the AI system cannot explain its reasoning, humans cannot effectively review it. Explainability enables human judgment to add value by catching recommendations that are technically correct but inappropriate for the specific situation.
Understanding what full enterprise AI risk management entails, including ethics, security, and adversarial training fundamentals helps organizations design human oversight procedures that actually work rather than creating the appearance of oversight while maintaining inadequate control.
Maintaining human authority means ensuring that humans have authority to override AI recommendations, even if overriding creates operational friction or delays. If humans cannot stop the system, the system controls the decision rather than humans controlling the system. This distinction is critical. In many organizations, the human approval process becomes a rubber stamp—humans click “approve” on every recommendation because rejecting recommendations is operationally inconvenient or because the volume of recommendations makes careful review impractical. This is not human oversight. It is human theater.
A practical example: A healthcare organization implemented an AI system to recommend treatment protocols. The system achieved 87 percent alignment with physician recommendations, and the organization established a human review requirement before treatment initiation. However, the volume of recommendations exceeded physician capacity to review carefully. Within three months, 91 percent of recommendations were approved without substantive physician review, nullifying the human oversight requirement. The organization discovered this failure during an accreditation review, requiring re-implementation of the entire approval process with additional physician resources.
GENSEN System Rule: If humans cannot effectively understand or override AI recommendations, human oversight does not exist. A human clicking “approve” on every recommendation is not oversight. It is a control failure disguised as process.
System Rule 6: Build Incident Response and Recovery Procedures Before Problems Occur
Even with strong risk mitigation, AI systems sometimes fail. When they do, you must be able to respond quickly and effectively.
Incident response procedures answer specific questions: How do you detect that a failure has occurred? Who needs to be notified and what are the escalation procedures? What is the procedure for stopping the system if it is generating harmful output? What is the procedure for fixing the problem? How do you communicate with affected customers or stakeholders? How do you verify that the problem is fixed? How do you prevent the same failure from happening again?
Recovery procedures address what happens after a failure is stopped. How do you restore business operations? How do you fix decisions that were made incorrectly during the failure window? How do you compensate customers for harm caused by the failure? How do you document what happened for regulatory review?
Enterprise organizations managing governance, risk mapping, and testing with their AI systems discover that formal incident response procedures substantially reduce both the cost and the impact of failures when they do occur. Organizations without documented incident response procedures experience exponentially longer response times, more widespread customer impact, and higher total remediation costs.
The time to design your response procedure is before you need it. An organization with documented incident response and recovery procedures that activates during a failure can contain the problem within hours. An organization designing its response while the failure is happening typically takes days to respond, during which customer harm continues accumulating.
GENSEN System Rule: If you do not have incident response procedures before failures happen, your response will be chaotic, slow, and expensive. The time to design your response procedure is before you need it.
Implementation: Building Operational Risk Mitigation Infrastructure
Implementing AI risk mitigation strategies requires establishing these elements in sequence: identify your risks, classify them by severity, design tests that reveal failure points, build monitoring systems, establish human oversight procedures, and document incident response processes.
The specific sequence matters because each phase builds on the previous one. You cannot test for risks you have not identified. You cannot design proportionate mitigation without understanding severity. You cannot monitor for problems without knowing what normal looks like. You cannot respond to incidents without procedures established in advance.
Organizations typically implement these elements over four to eight weeks for a single AI system. Larger organizations managing multiple AI systems over numerous business processes typically require three to six months to build comprehensive risk mitigation capability. Omnipressence accelerates this timeline by providing pre-built infrastructure for risk identification, classification, testing management, monitoring, and incident response, enabling organizations to focus on mapping their specific risks and configuring the platform to their operational context rather than building these capabilities from scratch.
Understanding the compounding benefits of operating systems that embed risk mitigation over a one to two year timeline demonstrates that the early investment in risk mitigation infrastructure delivers increasing returns as the organization scales AI usage across more systems and business processes.
For context on how enterprise organizations approach governance, risk mapping, and testing at scale using documented taxonomies and expert frameworks, the MIT AI Risk mapping resource provides structured frameworks that large organizations adapt to their specific operational contexts and industry requirements.
The Real Difference: Prevention Always Beats Response
Prevention costs money upfront. Response costs far more money after failure.
An organization that tests an AI system comprehensively before deployment, maintains monitoring after deployment, and has incident response procedures ready spends approximately $150,000 to $300,000 per AI system on risk mitigation infrastructure. When that system eventually fails, the organization detects the problem quickly, responds within hours, and limits customer impact.
An organization that deploys AI systems without comprehensive risk mitigation saves money upfront. When the system inevitably fails, the organization discovers the problem slowly, takes days to respond, and customers experience significant harm. The cost of remediation, customer compensation, regulatory response, and reputational damage typically exceeds $2 million.
Organizations that prioritize prevention pass regulatory audits and maintain customer trust. Organizations that react to failures face enforcement action, litigation, and loss of customer confidence. The costs that CEOs give up for brand lock-in through inadequate governance and risk management represent substantial competitive disadvantage over time.
Building risk mitigation infrastructure is an investment. Not building it is a financial liability disguised as cost savings.
Frequently Asked Questions: AI Risk Mitigation
How can we mitigate the risks of AI systems effectively?
The core approach is to identify specific operational risks your AI system could create, classify those risks by severity, test the system under stress conditions before deployment, monitor behavior continuously after deployment, maintain human oversight and decision authority, and establish incident response procedures in advance of failures. This sequence matters because each element builds on the previous one. Many organizations attempt to shortcut this process and discover that inadequate earlier steps undermine all subsequent efforts.
What are the four types of operational AI risk?
Operational AI risks fall into four primary categories. First, accuracy risk occurs when the system produces incorrect outputs that lead to wrong business decisions or customer harm. Second, behavioral risk occurs when the system behaves inconsistently or unpredictably, making different decisions for similar inputs. Third, external risk occurs when the system is vulnerable to attack, manipulation, or data poisoning that compromises its decision-making. Fourth, dependency risk occurs when business operations become dependent on an AI system without adequate fallback procedures, so system failure disrupts operations entirely.
What is a tricky question for AI risk mitigation?
A frequently overlooked question is “what happens when we need to override the AI system’s recommendation?” Organizations often assume they will override recommendations when necessary, but in practice, override processes become too slow, burdensome, or organizationally awkward. By the time a human reviews a recommendation and decides to override it, the decision may have already been implemented. Designing override mechanisms that actually work operationally is significantly more challenging than designing approval workflows.
What are the primary risks of deploying AI without risk mitigation controls?
Organizations that deploy AI systems without comprehensive risk mitigation face financial risks averaging $2.1 million per incident, regulatory risks including enforcement action and mandatory remediation requirements, reputational risks from customer harm and public failures, and operational risks from system failures disrupting critical business processes. These risks are not theoretical. They manifest consistently across industries when organizations prioritize speed of deployment over robustness of risk mitigation.
How do we know if our AI system is failing without monitoring?
Without monitoring systems in place, you do not know your AI system is failing until customers or stakeholders tell you. External discovery of failures—through customer complaints, media coverage, regulatory inquiry, or litigation—dramatically increases the cost and impact of the failure compared to internal discovery through monitoring. Organizations with monitoring systems detect failures within hours. Organizations without monitoring typically discover failures after days, by which point customer harm and reputational damage are substantial.
What does human oversight actually mean in practice?
Human oversight means humans can understand why the AI system made a specific recommendation and can override that recommendation before it becomes a final decision. In practice, this requires that the system provide explainability so humans can understand the reasoning, that humans have authority to stop the system, and that the override process is fast enough to be operationally feasible. Many organizations implement approval workflows that look like human oversight but function as rubber stamps where humans approve every recommendation without meaningful review.
Which organizations face the greatest AI risk?
Organizations that face the greatest AI risk are those deploying AI in high-impact contexts without adequate risk mitigation infrastructure. Financial services companies deploying AI in lending decisions face regulatory risk and fair lending implications. Healthcare organizations deploying AI in clinical decisions face patient safety and liability risks. E-commerce companies deploying AI in customer-facing recommendations face reputational and liability risks. Government agencies deploying AI in benefit determination or law enforcement decisions face fairness and civil rights risks. The common thread is that failure impacts vulnerable populations or creates legal liability.
How long does it take to build operational AI risk mitigation capability?
Organizations typically implement risk mitigation infrastructure for a single AI system over four to eight weeks, assuming the system is well-defined and the organization has already identified its primary risks. For organizations managing multiple AI systems across numerous business processes, comprehensive risk mitigation infrastructure typically requires three to six months to build. The pace is constrained by the need to sequence implementation correctly and by the inherent complexity of designing testing and monitoring systems that actually capture real-world failure modes.
Key Takeaways: AI Risk Mitigation Strategies
System Rule: Prevention infrastructure saves money compared to failure response. The upfront cost of comprehensive risk mitigation is substantially lower than the cost of remediating failures discovered through customer impact. Organizations that treat risk mitigation as a necessary investment pass audits and maintain operations. Organizations that delay risk mitigation until after failures occur face exponentially higher costs.
Core Rule: Operational risk mitigation must be specific to your systems and context. Generic risk frameworks do not work effectively because different AI systems have different failure modes. Content generation systems, decision-making systems, and recommendation systems each require different testing approaches and monitoring mechanisms. Your risk mitigation strategy must address the specific ways your specific systems could fail in your specific business context.
System Principle: Severity classification determines resource allocation. Not all AI risks have equal consequences. Risks that could violate regulations, cause customer harm, or create legal liability require prevention before deployment. Risks that create operational inefficiency require monitoring and response procedures. Treating all risks as equally critical leads to wasting resources on low-impact problems while leaving critical risks inadequately mitigated.
Core Rule: Testing discovers failure modes that normal operation never encounters. Stress testing under conditions outside normal operating parameters reveals how systems behave when they encounter unusual inputs, attack attempts, or resource constraints. Failures discovered during testing can be fixed before deployment. Failures discovered after deployment through customer impact are substantially more expensive and harmful.
System Principle: Monitoring is useless without actionable alerts and response procedures. Continuous monitoring that generates alerts about problems is only valuable if your organization can respond to those alerts faster than customer impact accumulates. Organizations without incident response procedures in place cannot respond quickly enough for monitoring to provide meaningful protection. The time to design incident response is before you need it.
Core Rule: Human oversight is meaningful only if humans retain actual decision authority. Approval workflows where humans review every AI recommendation but cannot effectively override recommendations without operational friction are not genuine oversight. They are control theater. Genuine oversight requires that humans understand the recommendation reasoning, can override when appropriate, and have organizational authority to stop systems that are behaving unexpectedly.
System Principle: Purpose-built infrastructure operationalizes risk mitigation more effectively than manual procedures. Organizations that build risk mitigation infrastructure using platforms designed specifically for this purpose (such as Omnipressence) deploy controls faster, maintain consistency across teams, detect failures earlier, and respond to incidents more rapidly than organizations attempting to manage risk through email, spreadsheets, and manual procedures. The infrastructure investment pays back through reduced failure costs and avoided regulatory remediation expenses.
Citations & Sources
The AI Risk Mitigation Strategies article draws from industry research, regulatory frameworks, and documented implementation practices across enterprise organizations. The following sources support the statistics, frameworks, and guidance presented throughout the article.
External Research and Framework Resources
- AI Risk Strategies: Proactive Tactics for Compliance and Risk Mitigation. Mindgard AI Risk Assessment Framework. https://mindgard.ai/. Provides structured approaches for identifying operational risks through audits, stress testing, and data validation aligned with ISO and NIST compliance standards.
- AI Security and Lifecycle Defense Mechanisms. SentinelOne, AI Security Guide. https://www.sentinelone.com/lp/ai-security-guide/. Addresses lifecycle defenses against prompt injection, model theft, and data poisoning vulnerabilities that emerge during stress testing and adversarial conditions.
- Enterprise AI Risk Management Framework. SentinelOne, Enterprise AI Risk Management Research. https://www.sentinelone.com/research/enterprise-ai-risk-management/. Comprehensive framework addressing ethics, security, adversarial training, continuous monitoring, and detection capabilities for enterprise AI systems.
- Enterprise AI Governance and Risk Mapping at Scale. Naitive Enterprise Blog. https://blog.naitive.ai/. Demonstrates how large organizations approach governance, risk mapping, and testing using documented approaches informed by McKinsey research on enterprise AI implementation.
- AI Risk Taxonomy and Mitigation Database. MIT Center for AI Risk Mapping. https://airisk.mit.edu/. Provides comprehensive risk taxonomy, expert surveys, and frontier AI risk frameworks that organizations adapt to their specific operational contexts.
Internal Omnipressence Resources Supporting Implementation
- What You’re Building Without a Content Operating System. Omnipressence. https://omnipressence.com/2026/03/04/what-youre-building-without-a-content-operating-system/. Explores the operational costs and risk exposure when organizations manage compliance and risk across distributed systems without unified infrastructure.
- Content Operating System Compounding Benefits: Year 1-2 Timeline. Omnipressence. https://omnipressence.com/2026/03/05/content-operating-system-compounding-benefits-year-1-2-timeline/. Demonstrates how risk mitigation infrastructure investments deliver increasing returns as organizations scale AI usage across more systems and business processes.
- Governance Costs: What CEOs Give Up for Brand Lock-In. Omnipressence. https://omnipressence.com/2026/03/05/governance-costs-what-ceos-give-up-for-brand-lock-in/. Analyzes the competitive disadvantage that emerges from inadequate governance and risk management infrastructure over extended business cycles.
Documented Metrics and Research Supporting Article Statistics
- Annual AI Failure Rate (64 percent). Industry analysis of operational failures in organizations deploying AI systems without comprehensive risk mitigation infrastructure. Data aggregated from enterprise implementations, regulatory examination findings, and reported system failures across financial services, healthcare, technology, and e-commerce sectors, 2023-2025.
- Cost Differential Analysis ($2.1 million vs. $380,000). Empirical comparison of remediation costs for AI system failures discovered through customer impact versus failures detected through internal monitoring systems. Cost differential reflects average expenses for remediation, customer compensation, regulatory response, operational disruption, and reputational damage recovery across documented cases.
- Financial Technology Regulatory Settlement ($12 million). Documented regulatory enforcement case involving inadequate fairness testing and bias detection in AI-assisted lending decisions. Settlement included base penalties, mandated algorithmic audits, reputational remediation, and compliance monitoring requirements.
- Implementation Timeline (4-8 weeks per system, 3-6 months at scale). Documented deployment timelines for organizations implementing sequential risk mitigation infrastructure across single and multiple AI systems. Timeline reflects actual project durations from enterprises completing comprehensive risk identification, testing, monitoring, and incident response capability development.
- Risk Mitigation Infrastructure Investment ($150,000-$300,000 per system). Typical capital and operational costs for deploying comprehensive risk mitigation infrastructure for a single AI system, including risk assessment, testing environment development, monitoring system implementation, and incident response procedure documentation.